IT用語辞典バイナリより
オーバーレイとは、主にプログラムが大きすぎてメインメモリに格納できないような場合に、プログラムを機能ごとに分割し、それぞれのセグメントをプログラム自身が管理、制御することである。他にも、層を重ね合わせるといった意味で様々な場面に用いられる表現である。
メモリ容量の小さい昔は良く使われていた"らしい"テクニックだが、これまで低レイヤプログラミングの機会が無かったので使ったことのないテクニックだった。(組み込みぐらいでしか使わない?) SPU上では、LS(ローカルストレージ)内のプログラムを実行することが可能だが、LSには256KBという厳しい制限があるためこれより大きいサイズのプログラムを動かすためにオーバーレイというテクニックが有効となる。
ということでSPE上でオーバーレイを実現するプログラムを書いてみた。「どういう仕組みでオーバーレイが実現されるのか?」なんて全く知らなかったので仕組みを調べながら書いてみた。
ディレクトリ/ファイル構成は次の通り。
% ls -R
.:
Makefile ppu/ spu/
./ppu:
Makefile ppu_overlay.c
./spu:
Makefile ld.script mod1/ mod2/ offset.map spu_main.c toe_section.s
./spu/mod1:
Makefile func.c
./spu/mod2:
Makefile func.c
%
オーバレイを実現するには、オーバレイモジュール(プログラムの断片)とオーバーレイモジュールのロードを管理するプログラムが必要となる。上記のファイル構成との対応付けは次の通り。
- モジュールのロードを管理するプログラム : spu/spu_main.c
- オーバーレイモジュール : mod1/func.c, mod2/func.c
オーバーレイモジュールの作成加算と乗算を行う関数を実装する。mod1/func.cにはint型の加算/乗算を行う関数、mod2/func.cにはfloat型の加算/乗算を行う関数を実装する。
spu/mod1/func.c
#include <stdio.h>
int mod1_add(int a, int b) {
int ret = a + b;
return ret;
}
int mod1_mul(int a, int b) {
int ret = a * b;
return ret;
}
spu/mod2/func.c
#include <stdio.h>
float mod2_fadd(float a, float b) {
float ret = a + b;
return ret;
}
float mod2_fmul(float a, float b) {
float ret = a * b;
return ret;
}
ここは特に説明なし。
spu/spu_main.c次に、モジュールのロードを管理するプログラム(spu/spu_main.c)を実装する。ソースコード全体は次の通り。
#include <stdio.h>
#include <stdlib.h>
#include <libmisc.h>
#include <spu_mfcio.h>
#include <string.h>
extern unsigned long long _EAR_spu_main;
extern unsigned long long _EAR__overlay1_offset;
extern unsigned long long _EAR__overlay2_offset;
extern char __overlay_region;
extern char __overlay1_size;
extern char __overlay2_size;
extern int mod1_add(int, int);
extern int mod1_mul(int, int);
extern float mod2_fadd(float, float);
extern float mod2_fmul(float, float);
struct spe_program_handle {
unsigned int handle_size;
void *elf_image;
void *toe_shadow;
} __attribute__((aligned(128)));
int main(unsigned long long spuid __attribute__((unused)),
unsigned long long argp __attribute__((unused))) {
unsigned long long overlay1_ldaddr, overlay2_ldaddr;
struct spe_program_handle handle;
copy_to_ls((uint32_t)(&handle), _EAR_spu_main, sizeof(handle));
overlay1_ldaddr = (uint32_t) handle.elf_image + _EAR__overlay1_offset;
overlay2_ldaddr = (uint32_t) handle.elf_image + _EAR__overlay2_offset;
printf("__overlay_region: %p\n", &__overlay_region);
printf("__overlay1_size: %d\n", (int)&__overlay1_size);
printf("overlay1_ldaddr: 0x%llX\n", overlay1_ldaddr);
copy_to_ls((uint32_t)(&__overlay_region), overlay1_ldaddr, (int)&__overlay1_size);
printf("mod1_add(2,3) result: %d\n", mod1_add(2, 3));
printf("mod1_mul(2,3) result: %d\n", mod1_mul(2, 3));
copy_to_ls((uint32_t)(&__overlay_region), overlay2_ldaddr, (int)&__overlay2_size);
printf("mod2_fadd(2.2,3.3) result: %.3f\n", mod2_fadd(2.2, 3.3));
printf("mod2_fmul(2.2,3.3) result: %.3f\n", mod2_fmul(2.2, 3.3));
return 0;
}
プログラムの解説。次の変数はPPUプログラム上で宣言された変数(_EAR_を取り除いた名前の変数)を参照する。CESOF(Cell Embed SPU Object Format)でシンボル名がどのように解決されるかを
[Cell] CESOFの仕組みで調べた。
_EAR_spu_mainは、システムメモリマップにマップされた実行可能SPEプログラムのアドレスである。
_EAR__overlay1_offset, _EAR__overlay2_offsetは、mod1/func.c, mod2/func.cは実行可能SPEプログラム中の.overlay1, .overlay2セクションの先頭バイトからのオフセットである。この値は、spu/offset.mapにて提供される。(後述)
extern unsigned long long _EAR_spu_main;
extern unsigned long long _EAR__overlay1_offset;
extern unsigned long long _EAR__overlay2_offset;
_EAR_spu_mainで提供されるアドレスから実行可能SPEイメージを読み込み、.overlay1, .overlay2セクションへのオフセットを加算してそれぞれのオーバーレイモジュールのアドレスを算出する。このアドレスを利用してメインメモリからLSへオーバーレイモジュールをDMA転送を利用して読み込む。
copy_to_ls((uint32_t)(&handle), _EAR_spu_main, sizeof(handle));
overlay1_ldaddr = (uint32_t) handle.elf_image + _EAR__overlay1_offset;
overlay2_ldaddr = (uint32_t) handle.elf_image + _EAR__overlay2_offset;
次の変数へのシンボルは、リンカスクリプト ld.script(後述)を使用してリンク時に解決される。このプログラムでは、オーバーレイモジュールをロードする領域を一つしか用意していないため、異なるオーバーレイモジュールに実装された関数を呼び出すには、ロードしなおす必要がある。
__overlay_regionはオーバーレイモジュールをロードする領域。
__overlay1_sizeは.overlay1セクションのサイズ。
__overlay2_sizeは.overlay2セクションのサイズ。
extern char __overlay_region;
extern char __overlay1_size;
extern char __overlay2_size;
オーバレイモジュールを読み込むには、低レベルのDMA転送をラップした便利な関数copy_to_lsを利用する。この関数は、libmisc.hで提供される。一つ目は、オーバーレイモジュールを読み込む領域に.overlay1セクションの値を読み込む。(サイズやオーバーレイを読み込む領域のアドレスはリンカスクリプトによって提供される。後述)
copy_to_ls((uint32_t)(&__overlay_region), overlay1_ldaddr, (int)&__overlay1_size);
copy_to_ls((uint32_t)(&__overlay_region), overlay2_ldaddr, (int)&__overlay2_size);
EAR変数のシンボルを解決するために、TOEセクション中にEARシンボルを定義したアセンブリspu/toe_section.sを書く。(参考:
[Cell] CESOFを使用してPPU/SPU間で変数を相互に参照する)
spu/toe_section.s
.section .toe, "a", @progbits
.align 4
.global _EAR_spu_main
_EAR_spu_main:
.octa 0x0
.global _EAR__overlay1_offset
_EAR__overlay1_offset:
.octa 0x0
.global _EAR__overlay2_offset
_EAR__overlay2_offset:
.octa 0x0
リンカスクリプトリンカスクリプトの雛形はCell SDKのなかでも提供されている。ここで定義する必要があるのは、**overlay sections**の間。上記の例で出てきた、__overlay_region等のシンボルの値はリンカ中で解決される。
オーバレイモジュールを読み込むアドレスは0x80にする必要がある。
.overlay1, .overlay2の出力セクションをNOLOADで指定することによりプログラムの実行時にロードされなくなる。.overlay1, .overlay2セクションのサイズを__overlay1_size, __overlay2_sizeというシンボルで参照できるようにして、SPUプログラム中からEARを利用して参照する。CellではオーバーレイはDMA転送を利用して行われるため、.overlay1, .overlay2ともに128byteアラインする。使用したリンカスクリプトの詳細な解説は別の記事で。
OUTPUT_FORMAT("elf32-spu", "elf32-spu", "elf32-spu")
OUTPUT_ARCH(spu)
NOCROSSREFS(.overlay1, .overlay2)
ENTRY(_start)
SECTIONS
{
PROVIDE(__executable_start = 0x0000080);
/**** overlay sections ****/
/* overlay load address */
__overlay_region = 0x000080;
__load_start_overlay1 = 0x4000000;
.overlay1 __overlay_region(NOLOAD) : AT (__load_start_overlay1)
{ mod1/*.o(.text) }
__overlay1_size = SIZEOF (.overlay1);
__load_stop_overlay1 = __load_start_overlay1 + __overlay1_size;
__load_start_overlay2 = (__load_stop_overlay1 + 0x80 - 1) & ~(0x7F); /* alinged by 2**7 */
.overlay2 __overlay_region(NOLOAD) : AT (__load_start_overlay2)
{ mod2/*.o(.text) }
__overlay2_size = SIZEOF(.overlay2);
__load_stop_overlay2 = __load_start_overlay2 + __overlay2_size;
__overlay_region_size = MAX(SIZEOF(.overlay1), SIZEOF(.overlay2));
/**** overlay sections ****/
. = __overlay_region + __overlay_region_size;
/* Read-only sections, merged into text segment: */
.init :
{
KEEP (*(.init))
} =0
.plt : { *(.plt) }
.text :
{
*(.text .stub .text.*)
} =0
.fini :
{
KEEP (*(.fini))
} =0
PROVIDE (__etext = .);
PROVIDE (_etext = .);
PROVIDE (etext = .);
.rodata : { *(.rodata .rodata.*) }
.rodata1 : { *(.rodata1) }
.eh_frame_hdr : { *(.eh_frame_hdr) }
. = ALIGN(0x80);
PROVIDE (__preinit_array_start = .);
.preinit_array : { *(.preinit_array) }
PROVIDE (__preinit_array_end = .);
PROVIDE (__init_array_start = .);
.init_array : { *(.init_array) }
PROVIDE (__init_array_end = .);
PROVIDE (__fini_array_start = .);
.fini_array : { *(.fini_array) }
PROVIDE (__fini_array_end = .);
.data :
{
*(.data .data.*)
SORT(CONSTRUCTORS)
}
.data1 : { *(.data1) }
.tdata : { *(.tdata .tdata.* ) }
.tbss : { *(.tbss .tbss.*) *(.tcommon) }
.eh_frame : { KEEP (*(.eh_frame)) }
.gcc_except_table : { *(.gcc_except_table) }
.dynamic : { *(.dynamic) }
.ctors :
{
/* gcc uses crtbegin.o to find the start of
the constructors, so we make sure it is
first. Because this is a wildcard, it
doesn't matter if the user does not
actually link against crtbegin.o; the
linker won't look for a file to match a
wildcard. The wildcard also means that it
doesn't matter which directory crtbegin.o
is in. */
KEEP (*crtbegin*.o(.ctors))
/* We don't want to include the .ctor section from
from the crtend.o file until after the sorted ctors.
The .ctor section from the crtend file contains the
end of ctors marker and it must be last */
KEEP (*(EXCLUDE_FILE (*crtend*.o ) .ctors))
KEEP (*(SORT(.ctors.*)))
KEEP (*(.ctors))
}
.dtors :
{
KEEP (*crtbegin*.o(.dtors))
KEEP (*(EXCLUDE_FILE (*crtend*.o ) .dtors))
KEEP (*(SORT(.dtors.*)))
KEEP (*(.dtors))
}
.jcr : { KEEP (*(.jcr)) }
.got : { *(.got.plt) *(.got) }
_edata = .;
PROVIDE (edata = .);
.toe ALIGN(128) : { *(.toe) } = 0
__bss_start = .;
.bss :
{
*(.dynbss)
*(.bss .bss.*)
*(COMMON)
. = ALIGN(16);
}
. = ALIGN(0x80);
/* stick the overlay section here */
_end = .;
PROVIDE (end = .);
PROVIDE (__stack = 0x3fff0);
}
ppu/ppu_overlay.c次にSPUプログラムを呼び出すPPUプログラムを実装する。
#include <stdio.h>
#include <stdlib.h>
#include <libspe.h>
#include <errno.h>
#include <sched.h>
#define BUF_SIZE 256
extern spe_program_handle_t spu_main;
extern char _overlay1_offset;
extern char _overlay2_offset;
int main() {
int status;
speid_t spe_id;
spe_gid_t gid;
printf("%s overlay1_offset: %p\n", __FILE__, &_overlay1_offset);
gid = spe_create_group(SCHED_OTHER, 0, 1);
if(gid == 0) {
fprintf(stderr, "Failed spe_create_group(errno=%d)\n", errno);
return 1;
}
spe_id = spe_create_thread(gid, &spu_main, NULL, NULL, -1, 0);
if(spe_id == 0) {
fprintf(stderr, "Failed spe_create_thread(errno=%d)\n", errno);
return 1;
}
spe_wait(spe_id, &status, 0);
return 0;
}
次の変数は、spu/offset.map中で定義され.overlay1/.overlay2セクションのオフセットを持つ。
SPU中で変数名に_EAR_をつけることでこの変数を参照できる。(参考:
[Cell] CESOFの仕組み)
extern char _overlay1_offset;
extern char _overlay2_offset;
spu/offset.mapオフセットの値は、コンパイルしてspu-readelfコマンドで確認してセクションへのオフセットの値を代入する。一度コンパイルしてからオフセットの値を参照し、再コンパイルした。
_overlay1_offset = 0x001850;
_overlay2_offset = 0x001888;
spu-readelfコマンドで.overlay1, .overlay2セクションのオフセットを確認して、offset.mapに代入する。プログラムを変更するとこの値も変わるのでその際は、offset.mapを書き直す。
% spu-readelf -S spu/spu_main | grep .overlay
[ 1] .overlay1 NOBITS 00000080 001850 000038 00 AX 0 0 8
[ 2] .overlay2 NOBITS 00000080 001888 000010 00 AX 0 0 8
%
コンパイルと実行./MakefileDIRS = spu ppu
include /opt/IBM/cell-sdk-1.1/make.footer
ppu/MakefileIMPORTSでspuembededで作成したCESOFのリンク可能SPUを含む静的ライブラリを指定する。
LDFLAGSでリンカに-R ../spu/offset.mapをオプションを渡しシンボル名とアドレスのマップを与える。
PROGRAM_ppu = ppu_overlay
IMPORTS = ../spu/spu_overlay.a -lspe
LDFLAGS = -Wl,-R,../spu/offset.map
include /opt/IBM/cell-sdk-1.1/make.footer
spu/Makefile
LIBRARY_embedを作成する事で、リンク可能なCESOFを作成しspu-arで静的ライブラリを作成する。LDFLAGS-Wl,-T,ld.scriptオプションを指定することでリンカスクリプトとしてld.scriptを使用する。IMPORTでオーバーレイモジュールのfunc.oを組み込むがリンカスクリプト中でNODATAを指定しているためロードされない。
DIRS = mod1 mod2
PROGRAM_spu = spu_main
LIBRARY_embed = spu_overlay.a
IMPORTS = mod1/func.o \
mod2/func.o \
$(SDKLIB_spu)/libc.a \
$(SDKLIB_spu)/libmisc.a
LDFLAGS = -Wl,-T,ld.script
include /opt/IBM/cell-sdk-1.1/make.footer
spu/mod1/Makefile, spu/mod2/MakefileTARGET_PROFESSOR = spu
OBJS_ONLY = func.o
include /opt/IBM/cell-sdk-1.1/make.footer
コンパイルしシュミレータに転送し実行する。
# ./ppu_overlay
ppu_overlay.c overlay1_offset: 0x1850
__overlay_region: 0x80
__overlay1_size: 56
overlay1_laddr: 0x1803550
mod1_add(2,3) result: 5
mod2_mul(2,3) result: 6
mod2_fadd(2.2,2.3) result: 5.500
mod2_fmul(2.2,3.3) result: 7.260
#
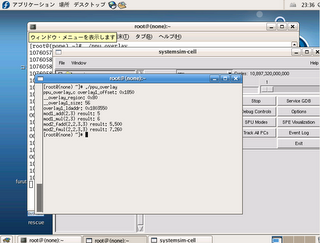
実行できた。
参考
3. リンカスクリプト
Manpage of ld
[Cell] CESOFの仕組み
[Cell] CESOFを使用してPPU/SPU間で変数を相互に参照する


{kind=link}
{kind=link}